

One of the main barriers to Large Language model deployment is the cost of inference. Lowering the computational footprint without hurting the quality of the model is an extremely hot topic in research due to the staggering costs that serving large language models entail.

The idea
As Machine Translation Large Language model researchers, we turned our attention to the obvious culprit: The output layer which represents the vocabulary of a Large Language model. It has dimensions HxV where H is the hidden layer dimension of the model and V is the vocabulary size. V is massive. For monolingual models such as LLaMa it's around 30,000 tokens but for multilingual models such as Bloom, it is more than 250,000! The output layer is the single largest matrix in the model, consumes a lot of memory, and its multiplication is quite costly.
In practice, however, we never make use of the full vocabulary at the same time. Most large language model queries and generations only contain a few dozens of tokens. If we could only somehow know in advance which tokens would be used during a generation, we could dynamically trim the vocabulary to a fraction of its full size.

The implementation
Dynamically reducing the size of the output layer is commonly used to speed up machine translation, as we can easily predict which words are going to be used in a translation, but the output of LLMs can be unbounded. How do we filter its vocabulary?
We can make the assumption that if a question is asked in English, the reply would also need to be in English. So we could reduce the vocabulary to the tokens only necessary for producing that language. We came up with not one but two separate ideas about how to achieve this!
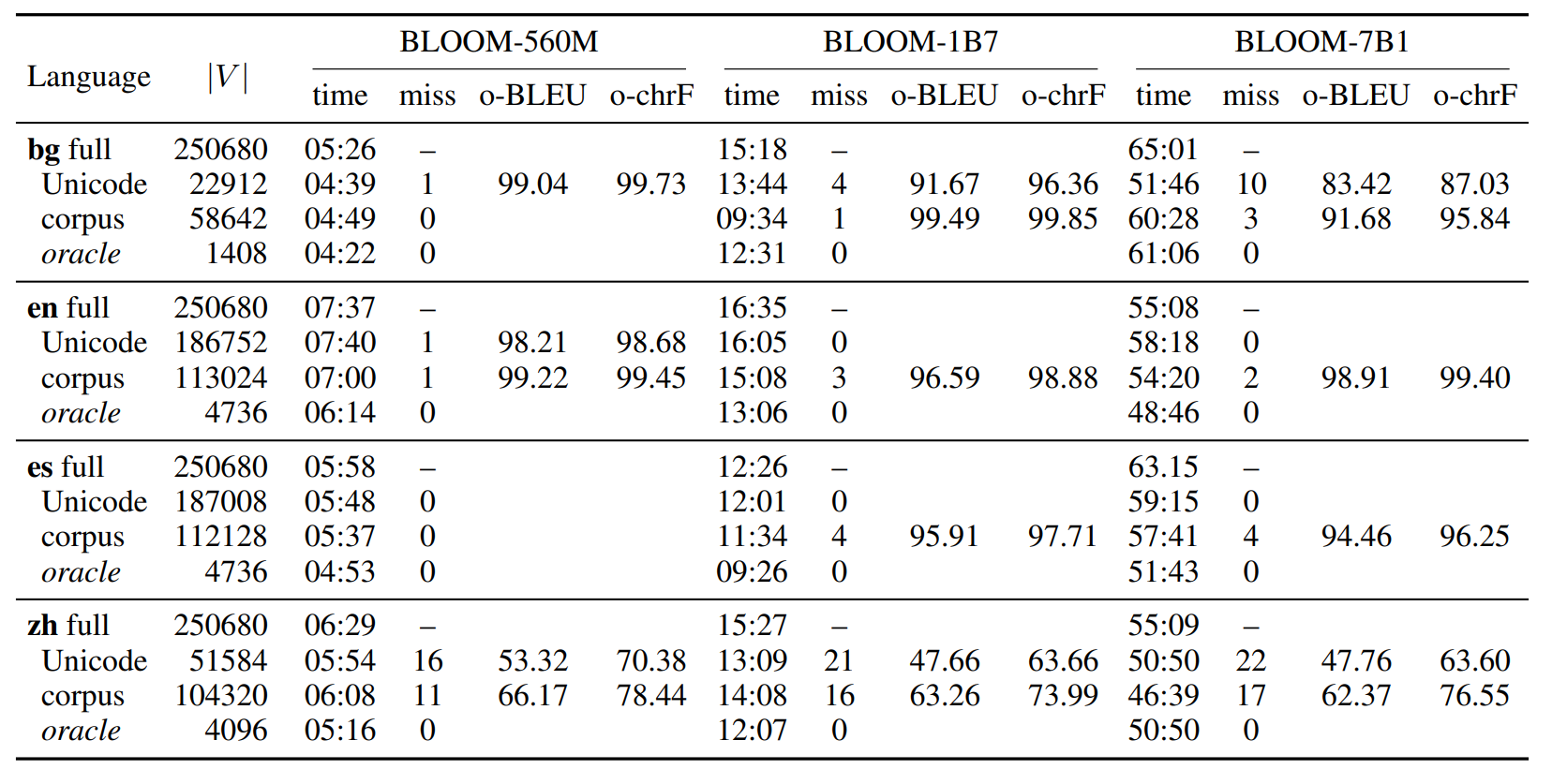
Unicode based trimming
Use the alphabet. LLMs, especially multilingual ones contain vocabulary for multiple languages which are written in different scripts. We can remove all vocabulary items that are written in a different script from the one our target languages uses. We call this the unicode method, as we filter vocab based on unicode ranges.
Corpus based trimming
Use a small representative corpus to build a dictionary. For example build a dictionary from newspaper articles in the language you are interested. This method has the advantage of allowing words through that possibly could be spelled in a different script (IE named entities from foreign countries may be spelled in a foreign script). We call this the corpus method.
Those heuristics are quite rough and we were sure we could come up with something better to further narrow the vocabulary, but we also wanted to produce an upper bound of how much performance we could hope to gain. In order to do that we performed an oracle experiment, where we run a decoding pass over 50 examples and we take a note of the vocabulary they used, and then we limit the model to use only those vocabulary tokens. This results in vocabulary of only a few thousand tokens which would be difficult to achieve in practice.
The ups
We did get some ups!
- We managed to reduce the decoding time by up to 20% in small models (25% if we consider the oracle experiment), but this is only when it comes to (comparatively) small 560M parameter models. Bigger models see only a modest 5-10% reduction in decoding time.
- Smaller vocabulary means less memory! We reduce the memory usage of the output layer by a factor of 10 in most cases!
The downs
- Speed increase is much lower in larger models, because vocabulary plays a lesser role in their computational footprint compared to small models (which are already quite fast on modern hardware).
- Memory reductions are insignificant for Large models, as the vocabulary represents just a tiny fraction of the total number of parameters...
- The quality of the generation drops. We expected the reduced vocabulary to produce identical generation to the full vocabulary but it turns out that things such as URLs and code samples mandate always Latin characters, but those were not available to our Chinese and Cyrillic models, resulting in more mismatches (labeled as misses on the table) and poorer generation quality. Chinese seems to suffer a lot more in this regard.
- The methods perform inconsistently with different languages. Latin script languages have harder time getting their vocabulary reduced by unicode matching; Likewise, it might be difficult to find a representative corpus for a lower resource languages:
Conclusion
We did achieve what we hoped for! We did improve generation speed.
However, in practice the methods we developed have limited practical use: It's very difficult to guarantee the quality with the reduced vocabulary which is a major show stopper. Furthermore, for large models the size of GPT-4, the computational cost in the output layer is tiny fraction compared to the cost of the attention.
Oh well, it's not all bad. Our methods could be useful for small models in memory constrained scenarios. We also saved other researchers time by publishing in the Workshop on insights from negative results in NLP!
Oh, and we got the best paper award!

If you are interested in the details, read the paper and cite us!
@inproceedings{bogoychev-etal-2024-ups,
title = "The Ups and Downs of Large Language Model Inference with Vocabulary Trimming by Language Heuristics",
author = "Bogoychev, Nikolay and
Chen, Pinzhen and
Haddow, Barry and
Birch, Alexandra",
editor = "Tafreshi, Shabnam and
Akula, Arjun and
Sedoc, Jo{\~a}o and
Drozd, Aleksandr and
Rogers, Anna and
Rumshisky, Anna",
booktitle = "Proceedings of the Fifth Workshop on Insights from Negative Results in NLP",
month = jun,
year = "2024",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.insights-1.17",
pages = "148--153",
}
Cya,
Nick, Patrick, Lexi, Barry