

Greetings fellow NLP-kind. I got a paper in BlackboxNLP 2021, the awesome workshop that aims to shed light on how, what, and why exactly happens inside deep neural networks... So I am going to blog about it.
The premise
The Deep Neural Network is an universal function approximator, that achieves surprisingly good results on a variety of tasks, thanks to its staggeringly large number of parameters and the infinite power and wisdom of backpropagation.

But is it really necessary to train all of those parameters? Could we just get away with training a small subset of those parameters and achieve similar performance? If we can, indeed, are some parameters more important than others?
The study
We study the value of training neural network parameters, as opposed to initialising them at random and freezing them. We perform a case study using neural machine translation and neural language modeling tasks, and transformers of various sizes and shape as the architecture.
We isolate three separate groups of parameters in a transformer: The embedding layer, the attention layer, and the FFN layer.
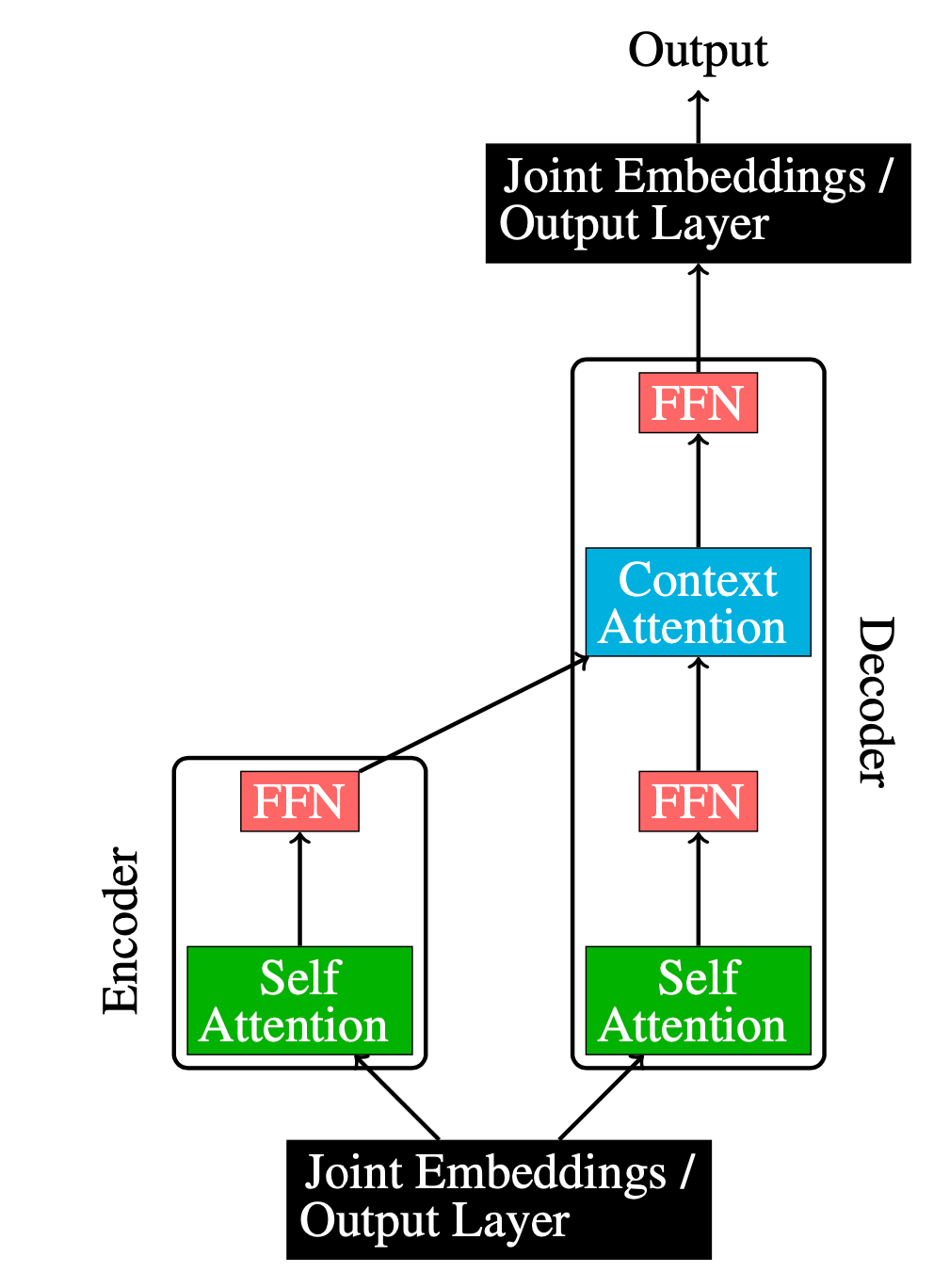
We perform an ablation study where one or two of the three components are initialised at random, frozen, and never trained afterwards until the neural network converges, and note how much quality has been affected.
The findings
We studied three different transformer presets for neural machine translation: big, base and tiny. In general, we found that bigger transformers have more built-in redundancy and cope better with parts of their parameters being frozen compared to smaller transformers.
Attention is mostly what you need.
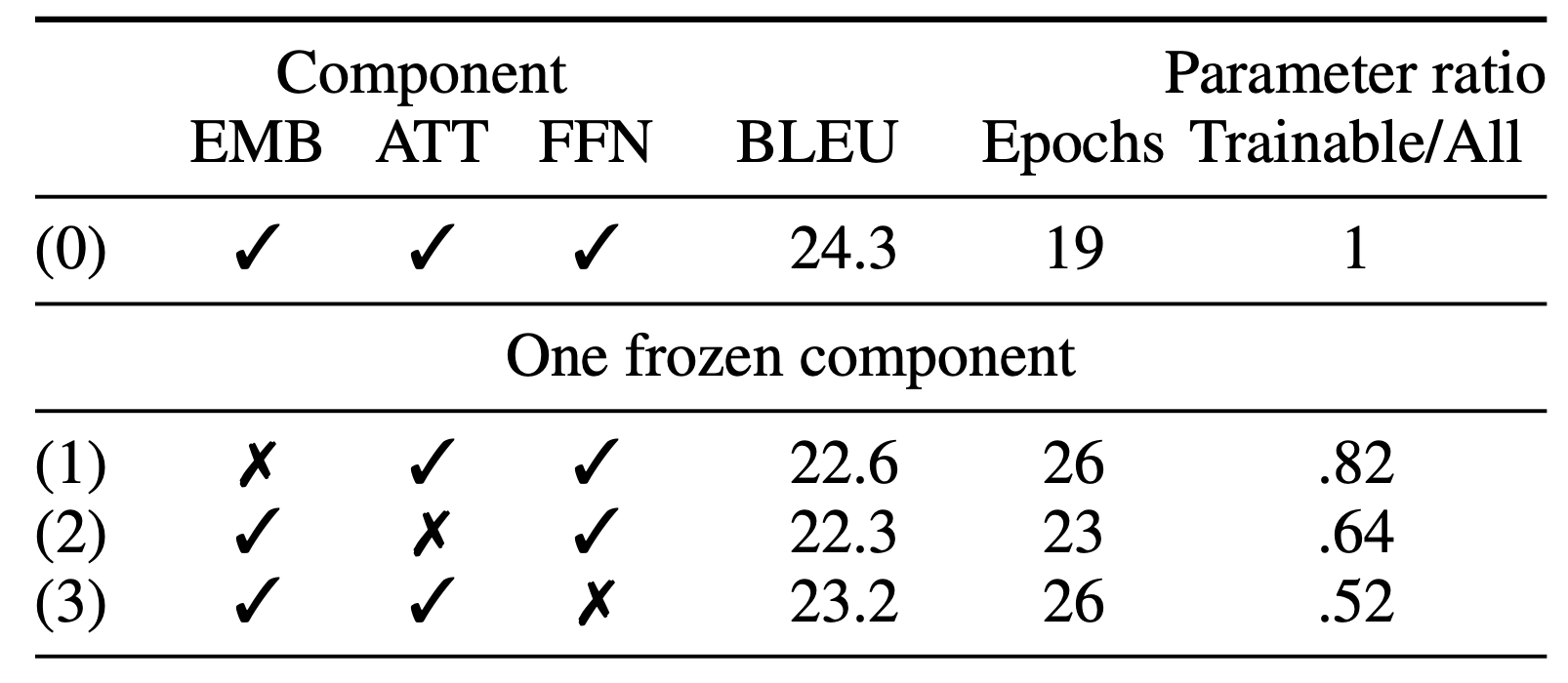
We found that when freezing one component of a transformer, the time to convergence increases slightly in terms of number of epochs, and the BLEU scores drop slightly (4%-7%). Preset (3), where we have a frozen and random FFN layer, and trainable embeddings and attention, performs the best, despite only 48% of the parameters being trainable.
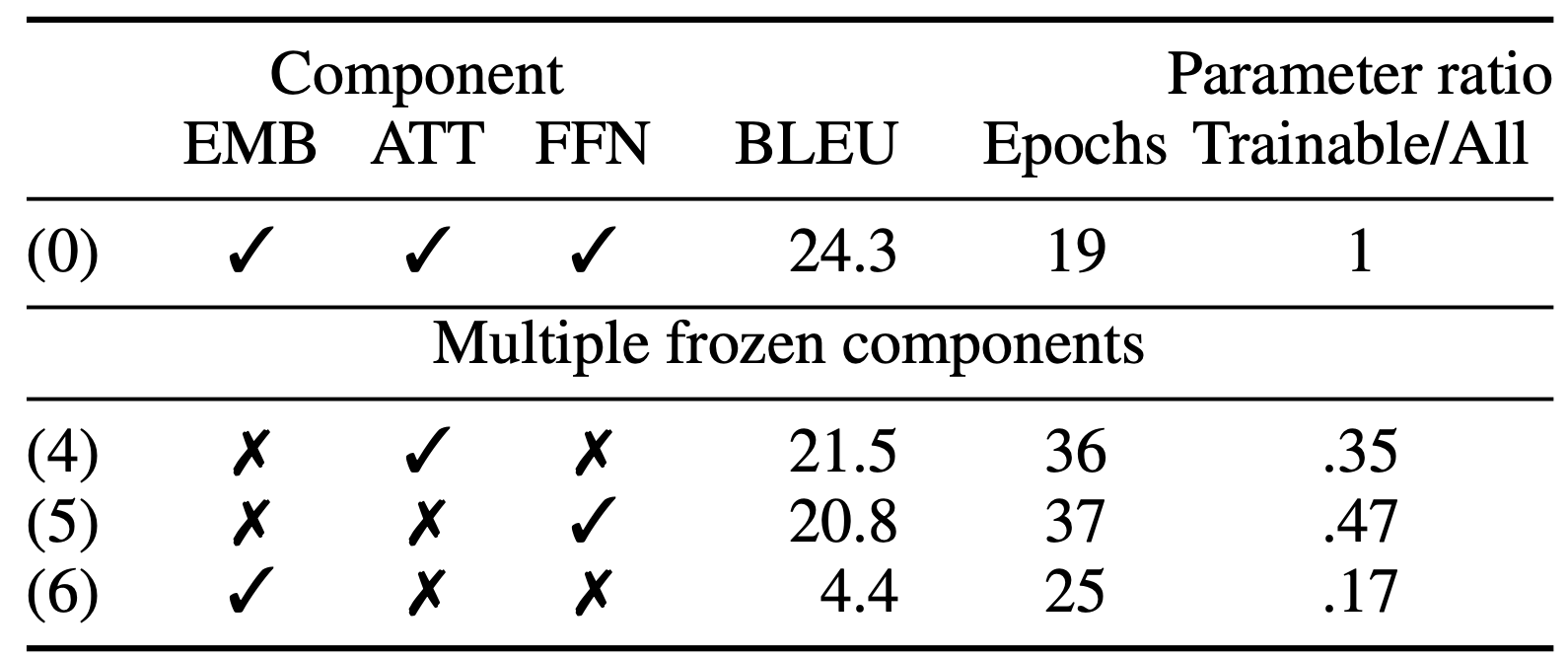
When freezing multiple components at once, we found that the best results are achieved by having just the attention be trainable, although just having the FFN trainable produces surprisingly good results as well. The only time where the model completely fails to learn is if we just have the embeddings trainable.
Not all parameters are born equal, but they are nevertheless necessary
Despite the attention and the FFN layer being more or less self-sufficient and much more important than the embedding layer, this doesn't mean we can just remove the embedding layer, or reduce its size. We perform a number of experiments and note that when reducing the size of frozen and random components, the model's performance suffers, even if the trainable components are left untouched. This suggests that the trainable components make use of the randomly initialised transformations and the sheer number of parameters is more important than whether they are trainable or not.
In our paper we show detailed results in a variety of different combinations of neural network configurations, but the overall trend holds true across all of them.
Language models behave differently
Language models find trainable embeddings much more important for achieving lower perplexity than trainable FFN or attention layer. The drop in perplexity is also a lot more dramatic than the drop in BLEU for translation models.
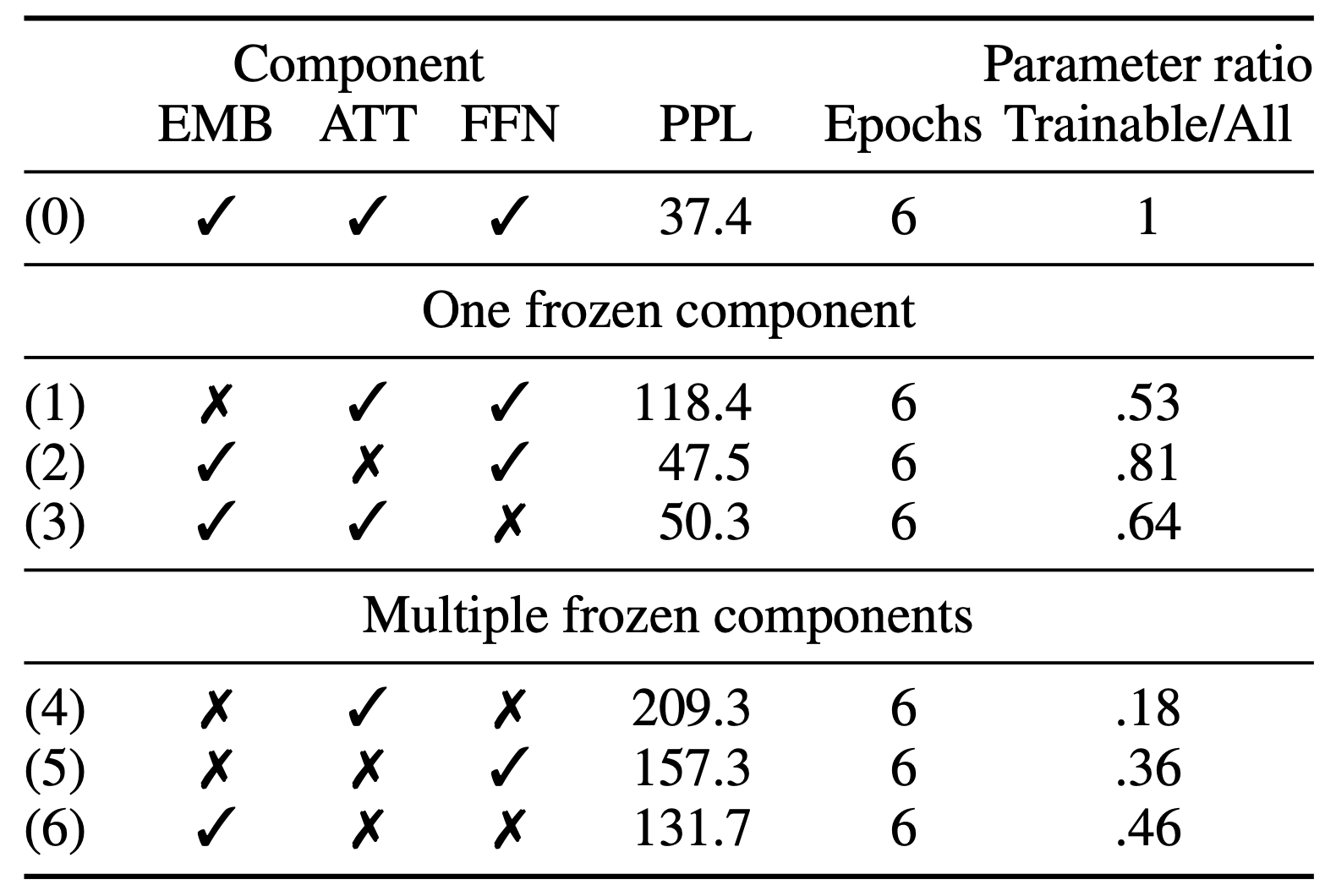
This suggests that our findings are likely to be task specific.
Implications
- We question that vast majority of the transfer learning work that relies on pretrained choose-your-sesame-street-character embeddings for use in downstream tasks. We believe that one should always attempt to solve the downstream task with randomly initialised embeddings before using an off-the-shelf solution in order to truly show the value (or lack thereof) of pretraining.
- Could this mean that we could potentially use a RNG in order to generate less important components on the fly during inference for memory efficient networks to be used on embedded devices.
- Neural networks are still a blackbox. This particular work is one in a long line of research in Echo State networks.
We have a lot more details, experiments and analysis in the paper. If interested, please check it out, and come talk to us at the BlackboxNLP 2021 poster session!!
Thank you for your time!
Nick