

One of the big challenges that I have had to tackle as a senior (at least in theory) machine translation researcher is how to explain to novices in the field what a good machine translation makes.

It's quite difficult to answer this question because there's no one single correct answer. The process is very long with lots of if-then-else decisions that need to be taken which makes it unnecessarily confusing to newcomers. Let's illustrate the basic process:
- Get parallel data
... - Train Neural Network
... - Profit
Parallel data
Unfortunately parallel data comes in many different shapes and forms. Every publicly available corpus has its own idiosyncracies and requires a personalised cleaning approach. To give some examples
- A lot of UN corpora have a comma at the line ending, as opposed to a full stop.
- Some corpora don't use French quotes (« ») when translating from English.
- Some Chinese corpora come tokenized, some don't.
- Some corpora have the direction inversed.
- ... Probably something else we have forgotten...
In order to do parallel data preprocessing right, we need to manually open and inspect each parallel corpus, see what is wrong with it, write a small script to fix it and move to the next one...

Tedious is one word that comes to mind when describing the process, especially considering that there are always dozens of distinct data sources for each language pair. And nobody wants to do something tedious.
Training
Assuming we somehow survived the data cleaning process, we are now faced with the equally daunting task of training a neural network. Easy, right?

Neural networks are notoriously fickle and break if you even as much as sneeze on them. Not fun. The problem is that all those data sources we talked about previously, no matter how hard we try to clean them, they will differ in quality. And it just so happens that neural networks like to see really simple data when they start training, and move onto more challenging data (or perhaps even noisy web data) later on in the training process. We may also want to:
- Incorporate backtranslation pretraining, before we start training on the whole data.
- Perform domain adaptation using in-domain corpora towards the end of the training.
- Balance the mix of web and human curated data as the former exceeds the latter by a factor of 10 at least.
All of those issues require stopping-and-starting the training process and swapping around the training data sources; merging different data sources together, with different sample ratios (and if you get those wrong, then you have to re-sample, re-balance and redo everything). What's the word? Tedium.
Humans
Finally, we built our nice little machine translation system, and it is time it face the ultimate challenge: End users. You build your lovely machine translation system and you give it to your user and what do they do with it? THEY TRY TO TRANSLATE ALL CAPS TEXT. Why is this a problem? Well, we don't have that much ALL CAPS text in our training data. Our neural network wouldn't know how to process it so it will produce crap.
Another common usecase is translating text that contains untranslateable characters. Those can be emoji 😉, or wikipedia articles:
The Quran (/kʊrˈɑːn/, kuurr-AHN;[i] vocalized Arabic: اَلْقُرْآنُ, Quranic Arabic: ٱلۡقُرۡءَانُ al-Qurʾān [alqurˈʔaːn],
The reason why emoji or text in foreign script often breaks translation systems is that it has not been seen during training. Sentences with large amounts of foreign text are filtered away from the training data as noisy. So how are we going to reproduce them?
The best way to do this is to ensure our training data contains lots of examples of this sort, so that the neural network easily learns how to reproduce them. But how exactly do we do that? We can sprinkle emoji at random, but that's not really a good solution if the data is fixed and the same emoji always appear in the same sentences. The neural network will just learn to anticipate the sentences containing emoji and not really learn to properly copy them... Ideally we want every iteration of our data to have some sentences that include emoji, but different ones every time. If we use a static data source, we need to replicate it many times just so we can have our neural network see different sets of noise at each iteration... Tedious
The solution:
In order to solve all of those issues we created a set of open source tools OpusCleaner and OpusTrainer, which aim to streamline the process, remove the tedium and solve the aforementioned (and many many other) issues.
OpusCleaner
OpusCleaner is a streamlined data-processing and visualisation toolkit that performs all the data cleaning tasks through a visual interface, minimising the number of clicks the user has to perform. First, we provide a one-stop-one-click data downloader so we can easily fetch all training data for a given language pair.
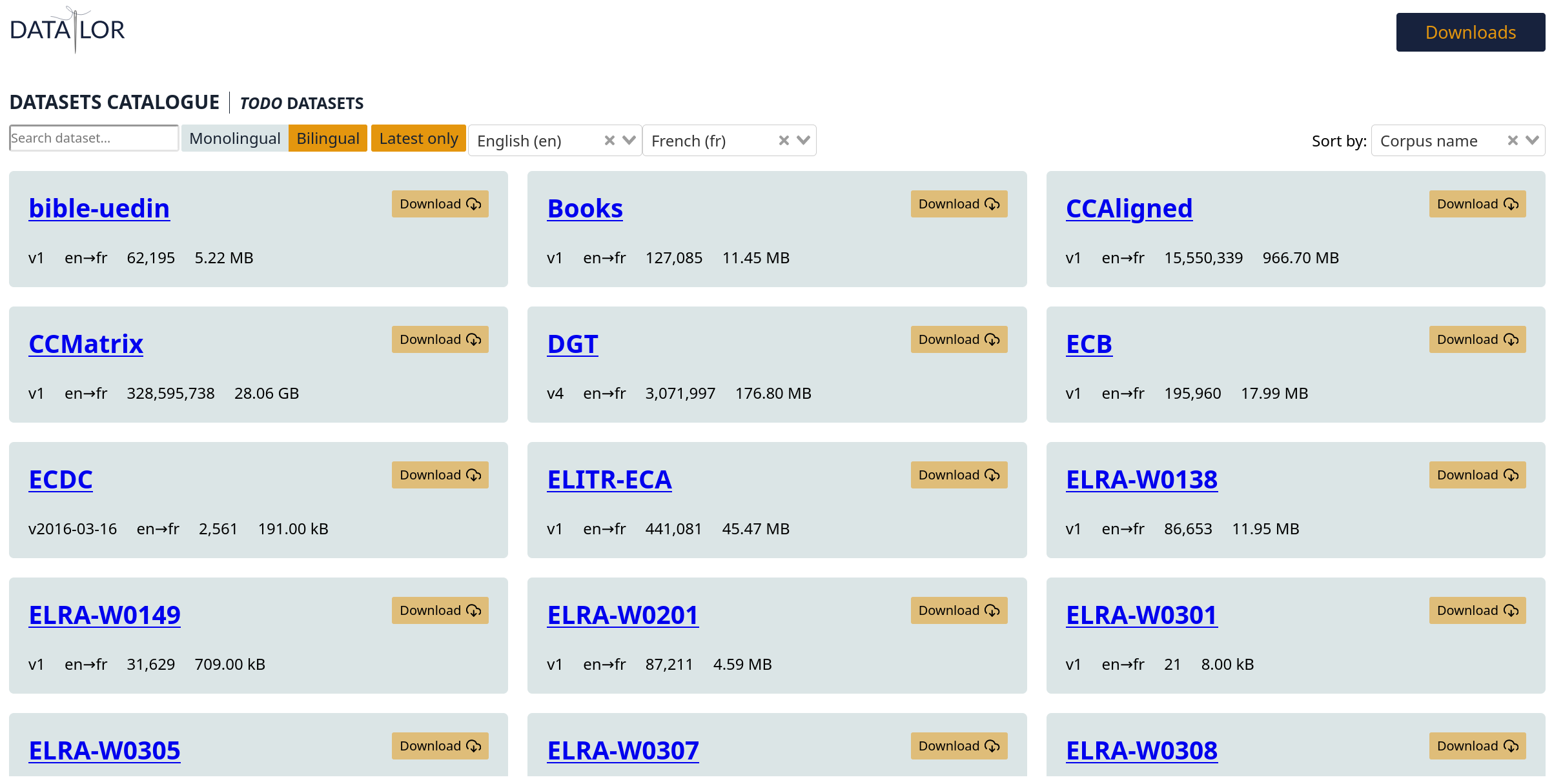
Then, for each dataset, we can visualise a random sample from it and perform drag-and-drop chaining of various different filters that will fix any issues we notice. Such as wrong language used:
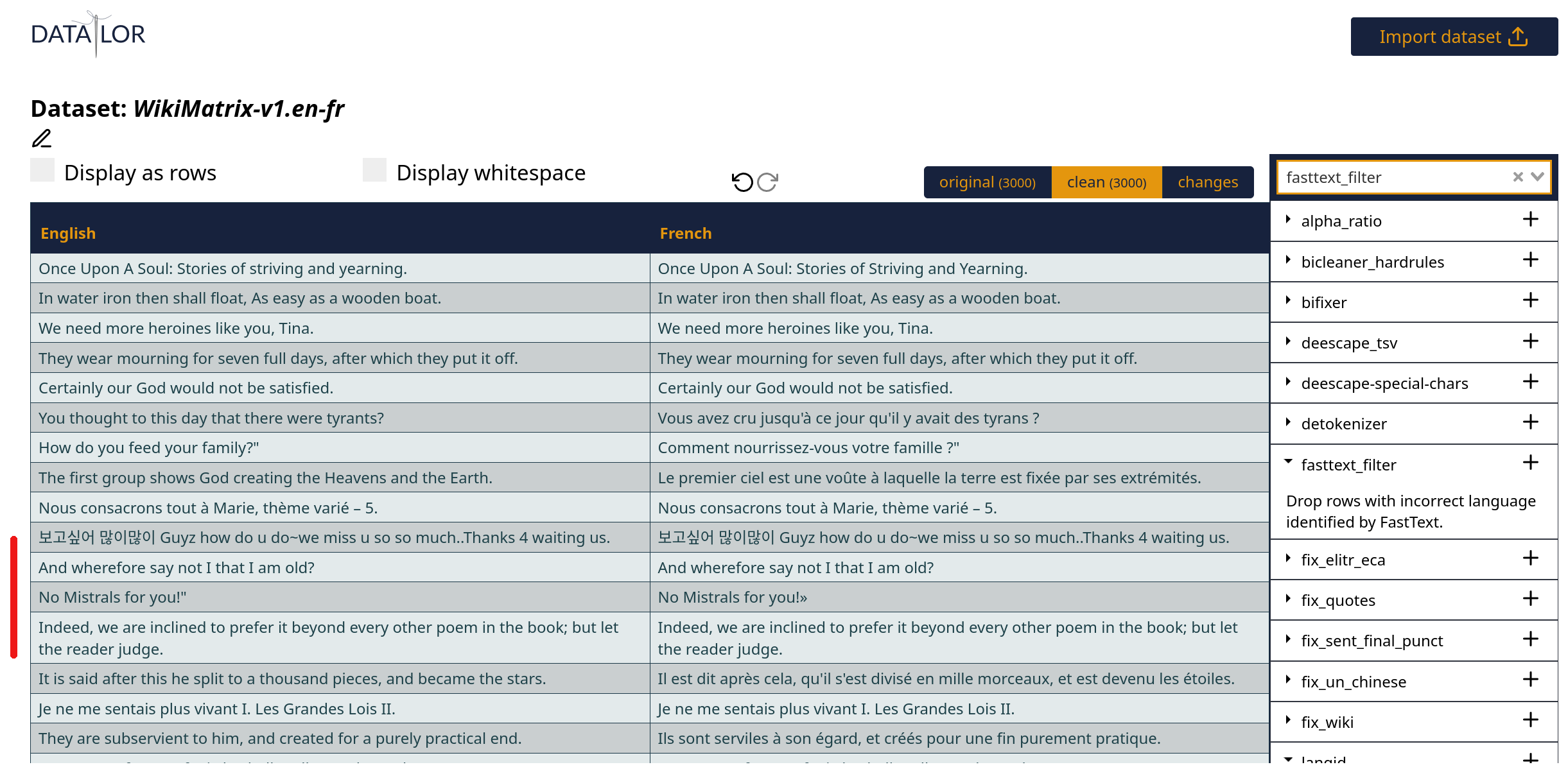
We can Apply fastText langID and voilà, suddenly a lot of lines from our sample are filtered out:
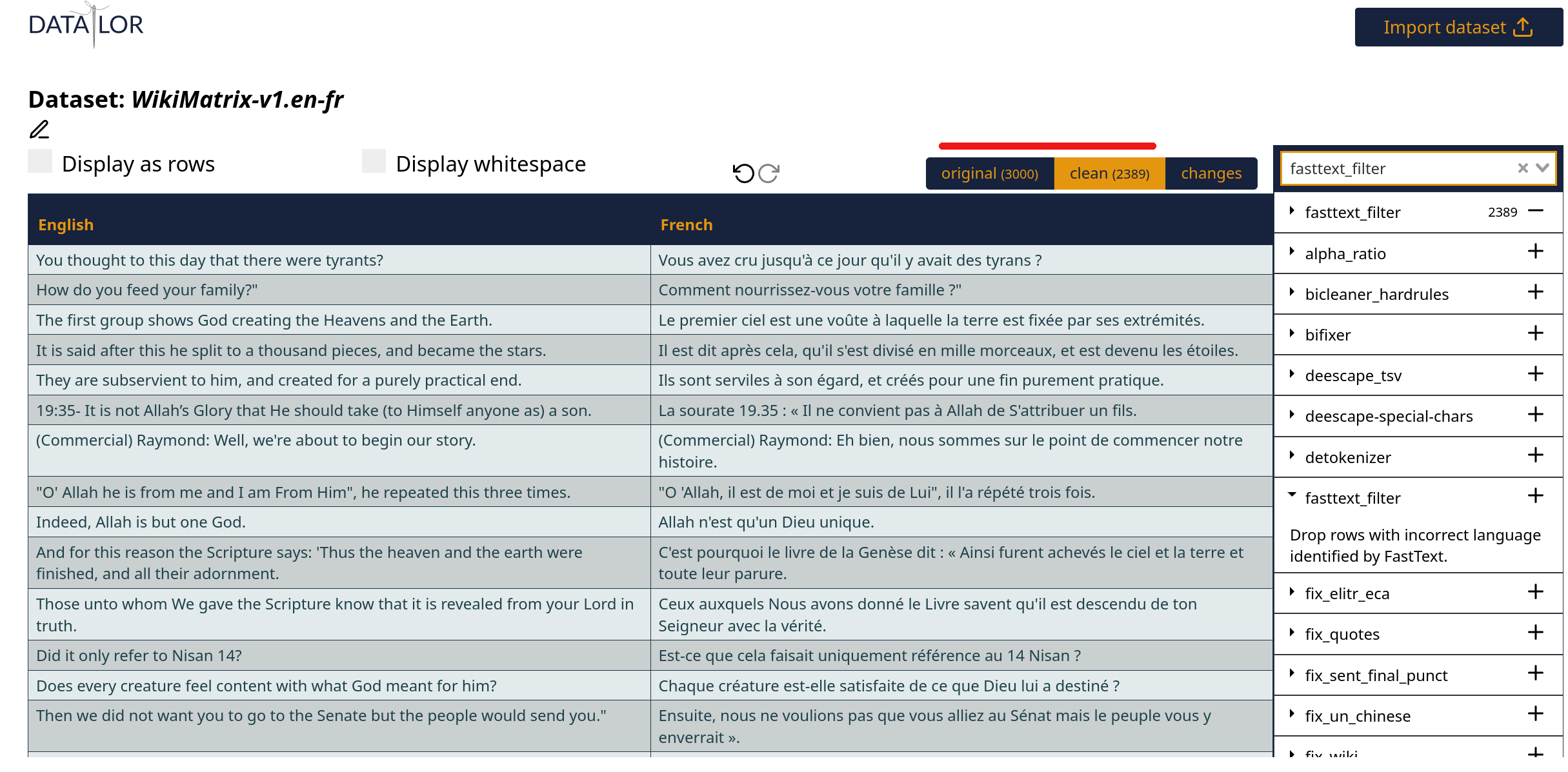
Presumably the ones that needed filtering, I hope. We can chain many different filters (on the right-hand side) and see how the sample changes after applying each of them:

Finally, you can assign a human-readable label to each dataset, and apply the filtering pipeline you have just defined to the full dataset:

Tadaaa! OpusTrainer is designed to save time and to turn data exploration and visualisation into an implicit step of the data cleaning process. This teachers new users important practical data skills and saves everyone tons of time!
OpusTrainer
OpusTrainer is a training set generator/augmenter. It is designed to provide a fast and easy way to define and produce different data mixes and augmentation using a yaml configuration file. We can define a rigorous training schedule, including pretraining on backtranslation, data mix ratios, and then have OpusTrainer generate that data and feed it to stdin of a neural network toolkit, or alternatively write it to a file:
datasets:
bt: bt.gz # 12.4 GB
cleanish: clean.gz # 2.4 GB
medium: medium.gz # 1.8 GB
dirty: dirty.gz # 33 GB
stages:
- start
- mid
- end
start:
- bt 0.9
- clean 0.1
- medium 0
- dirty 0
- until bt 1 # Until 1 epoch of bt
mid:
- clean 0.45
- medium 0.25
- bt 0.1
- dirty 0.2
- until clean 1
end:
- clean 0.25
- medium 0.25
- bt 0.1
- dirty 0.4
- until dirty inf
seed: 1111
More importantly, we can define data modifiers, that augment the training set on the fly with: UpperCase/TittleCase text; typos; Unicode noise (such as emoji/greek/chinese/any-random-script text), and more. And, the best part is that we only need to write a few lines of yaml to achieve this:
modifiers:
- UpperCase: 0.05 # Apply uppercase randomly to 5% of sentences. See below
- TitleCase: 0.05
- Typos: 0.05
- Tags: 0.005 # This introduces emoji/foreign text tokens
augment: 1
- Noise: 0.0005 # This introduces foreign text full sentences
min_word_legnth: 2 # Minumum lenght of each fake word, defaults is 2 if left blank
max_word_length: 5 # Maximum lenght of each fake word, defaults is 5 if left blank
max_words: 4 # Maximu number of fake words, default is 4 if left blank
An example French-English sentence pair from our data augmenter looks like this:
On a connu 🙁 😬 😭 la suite ! ↔ We know 🙁 😬 😭 the rest!
It looks a bit silly, but it gives our neural network an important signal that when it sees something silly, it should just copy it to the output and not think about it too hard :D.
- OpusTrainer augmentation allows us to get up to 92% accuracy on copying noisy foreign text in our translation systems, up from just 55% in the baseline, as described in my talk on Robust Machine Translation, at the 2023 MT Marathon.
A good example is attempting to translate the first sentence of the French Wikipedia article about the Quran. The sentence:
Le Coran (en arabe : القُرْآن, al-Qurʾān?, « la récitation ») est le texte sacré de 🕌 l'islam.
receives a somewhat lackluster translation due to the model's inability to cope with out-of-vocabulary characters.
The Qur'an (in Arabic: ااااااااااااااااااااااااااااااااااا, al-Qurاān?, "recitation") is the sacred text of u Islam.
But after applying OpusTrainer's UTF-8 noisy augmentation we get a significant improvement:
The Qur’an (Arabic: القُرْآن, al-Qurēn?, “recitation”) is the sacred text of 🕌 Islam.
- OpusTrainer augmentation allows for producing high quality terminology aware systems, such as the one described in Bogoychev and Chen (2023). Terminology aware systems allow us to enforce certain words to be translated in a particular way, overriding what the system thought would be best. For example, translating this German sentence into English yields a reasonable translation:
Was ist Ihr Herkunftsland?
What is your country of origin?
However, using a terminology aware system, we can apply a terminology constraint and force the word homeland to appear in the translation.
Was ist Ihr Herkunftsland __target__ homeland __done__?
What is your homeland?
Training configuraiton example for terminology-aware system is available on GitHub.
This project has been the result of a large collaboration by the consortium of the HPLT project. Our goal is to make it easier for anyone to build high quality machine translation systems by creating robust and mature data cleaner and data scheduler. Come and try it out! For questions specific to either OpusCleaner or OpusTrainer, open a GitHub issue!
For more details, please refer to the paper. Also, don't forget to cite us:
@misc{bogoychev2023opuscleaner,
title={OpusCleaner and OpusTrainer, open source toolkits for training Machine Translation and Large language models},
author={Nikolay Bogoychev and Jelmer van der Linde and Graeme Nail and Barry Haddow and Jaume Zaragoza-Bernabeu and Gema Ramírez-Sánchez and Lukas Weymann and Tudor Nicolae Mateiu and Jindřich Helcl and Mikko Aulamo},
year={2023},
eprint={2311.14838},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Thanks,
Nick